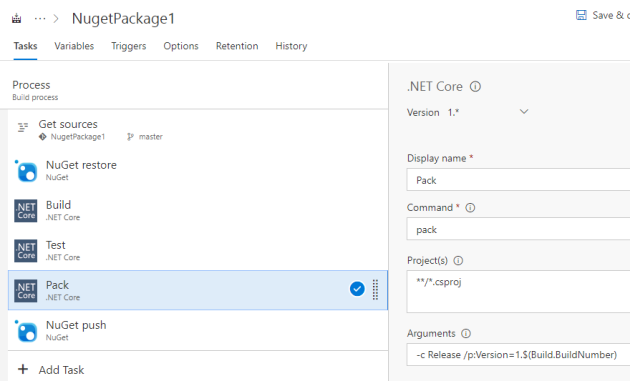
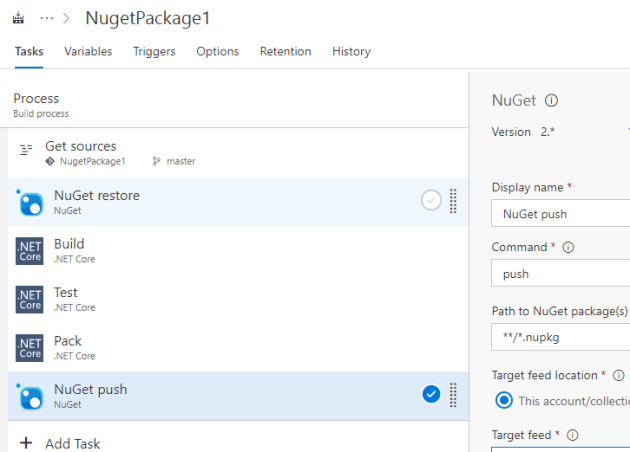
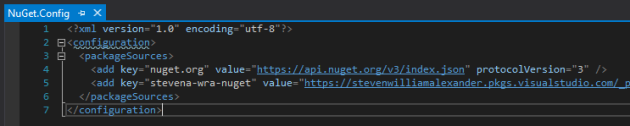
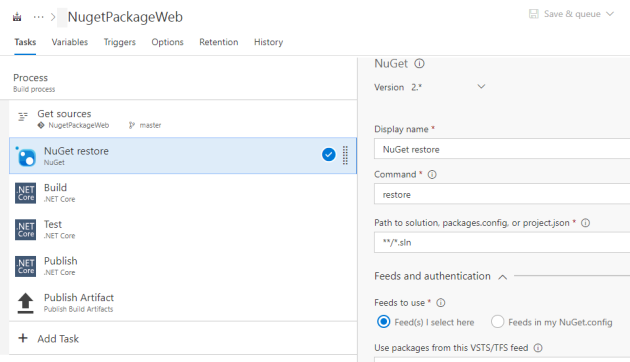
Starting out looking at serverless applications, it can be a bit intimidating for developers. You lose at lot of the built in functionality you are used to from traditiional web application frameworks and just getting something as simple as a basic web application running can be difficult.
I’m writing this as a guide for how to get started creating a web application that runs serverless, showing some approaches you can take.
Option 1 – Serve pure HTML from function and use public CDNs for static content
Use a serverless function (Lambda/Azure function etc.) to respond to HTTP requests by serving HTML, pointing to public CDNs for static content like JQuery or BootStrap. Custom JavaScript or CSS can be embedded directly in HTML. Can use micro web application frameworks in the function, like NodeJS Express, to generate the HTML response.
Advantages:
- Simplicity, you are creating and deploying only functions
- Easy to test locally, as you are only testing functions that serve HTML/HTTP responses
Disadvantages:
- Your custom CSS and JavaScript must be embedded directly in your HTML, cannot be cached and will bloat your responses
- Not normally suitable for production, doesn’t scale for complex web applications
Example:

Option 2 – Serve static HTML only from Bucket/Storage, as a single page application or for static GET requests with POST requests served by functions
Advantages:
- Static site hosting is cheap to run (low request volume) and normally easy to setup
- Can focus effort on using functions for simple API requests rather than serving more complex HTML
Disadvantages:
- Single page application, requires clientside JavaScript and different programming approach which not all developers are familar with
- Need either CORS setup to allow cross domain requests from browser JavaScript to functions or routing setup to serve both static site and functions from single domain. Requires significant setup
- Testing locally requires multiple elements running together
Example:

Option 3 – Use combination of functions and static served resources from Bucket/Storage, fronted by routing to build a web site for a single domain
Advantages:
- Can break up a complex web application into smaller parts, approach scales well
- Once routing is in place can expand to include other services/components easily
Disadvantages:
- Requires significant setup for routing to join together different components under single domain
- Testing locally requires multiple elements running together
Example:

Conclusion
If you are getting started I’d recommend starting small with the first approach, that way you can get to grips with the new tooling and serverless functions before you try more components. After you’ve done that you can expand to try more services with a decent foundation of knowledge (how to deploy, configure, test etc.) and won’t get overwhelmed with information.
Links
- aws-serverless-express – how to package your express application into a lambda function
- serverless framework – for generating serverless functions from templates and helping deploy them to cloud platforms
- AWS documentation on S3 static hosting
- Hosting Gatsby site in S3/Cloudfront
- AWS API Gateway creating proxy for multiple paths to lambda in web application or API