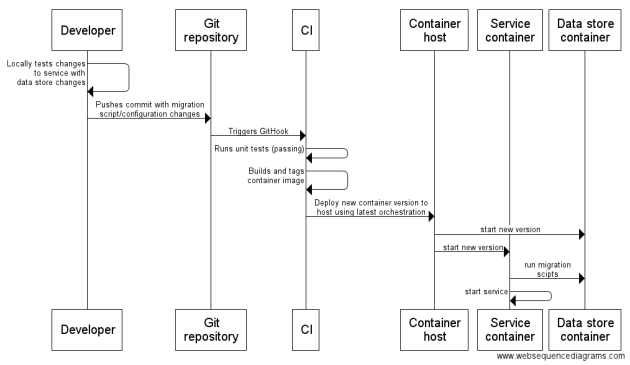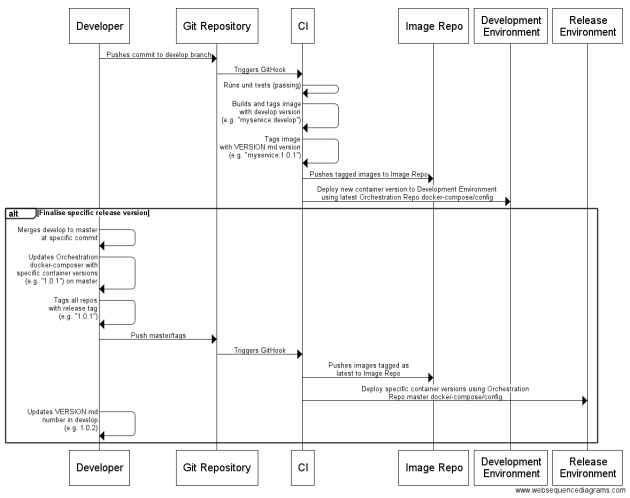
Been thinking a lot recently about how to manage versioning and deployment using Docker for a small scale containerised solution. It’s different from a traditional release pipeline as the build artifacts are the container images with the latest code and configuration, instead of the CI having a zip of the built application.
In a completely ideal containerised microservice solution all containers are loosely coupled and can be tested and built independently. Their CI configuration can be kept independent as well, with the CI and testing setup for the entire orchestrated solution taking the latest safe versions of the containers and performing integration/smoke tests against test/staging environments.
If your solution is smaller scale and the containers linked together, this is my proposed setup.
Build
Images should be built consistently, so dependencies should be resolved and fixed at point of build. This is done for node with npm shrinkwrap which generates a file fixing the npm install to specific dependency versions. This should be done as part of development each time package.json is updated, to ensure all developers as well as images use the exact same versions of packages.
On each commit to develop the image is built and tagged twice, once with “develop” to tag it as the latest version for develop branch code, and then with the version number in the git repo VERSION.md (“1.0.1”). You cannot currently build with multiple tags, but building images with same content/instructions does not duplicate image storage due to Docker image layers.
Tagging
The “develop” tagged image is used as the latest current version of the image to be deployed as part of automated builds to the Development environment, in the develop branch docker-compose.yml all referenced images will use that tag.
The version number tagged image, “1.0.1”, is used as a historic fixed version for traceability, so for specific releases the tagged master docker-compose.yml will reference specific versioned images. This means we have a store of built versioned images which can be deployed on demand to re-create and trace issues.
On each significant release, the latest version image will be pushed to the image repository with the tag “latest” (corresponding to the code in the master branch).